Andrej Karpathy @karpathy 2022-11-18
An interesting historical note is that neural language models have actually been around for a very long time but noone really cared anywhere near today’s extent. LMs were thought of as specific applications, not as mainline research unlocking new general AI paths and capabilities
Andrej Karpathy @karpathy 2022-11-18
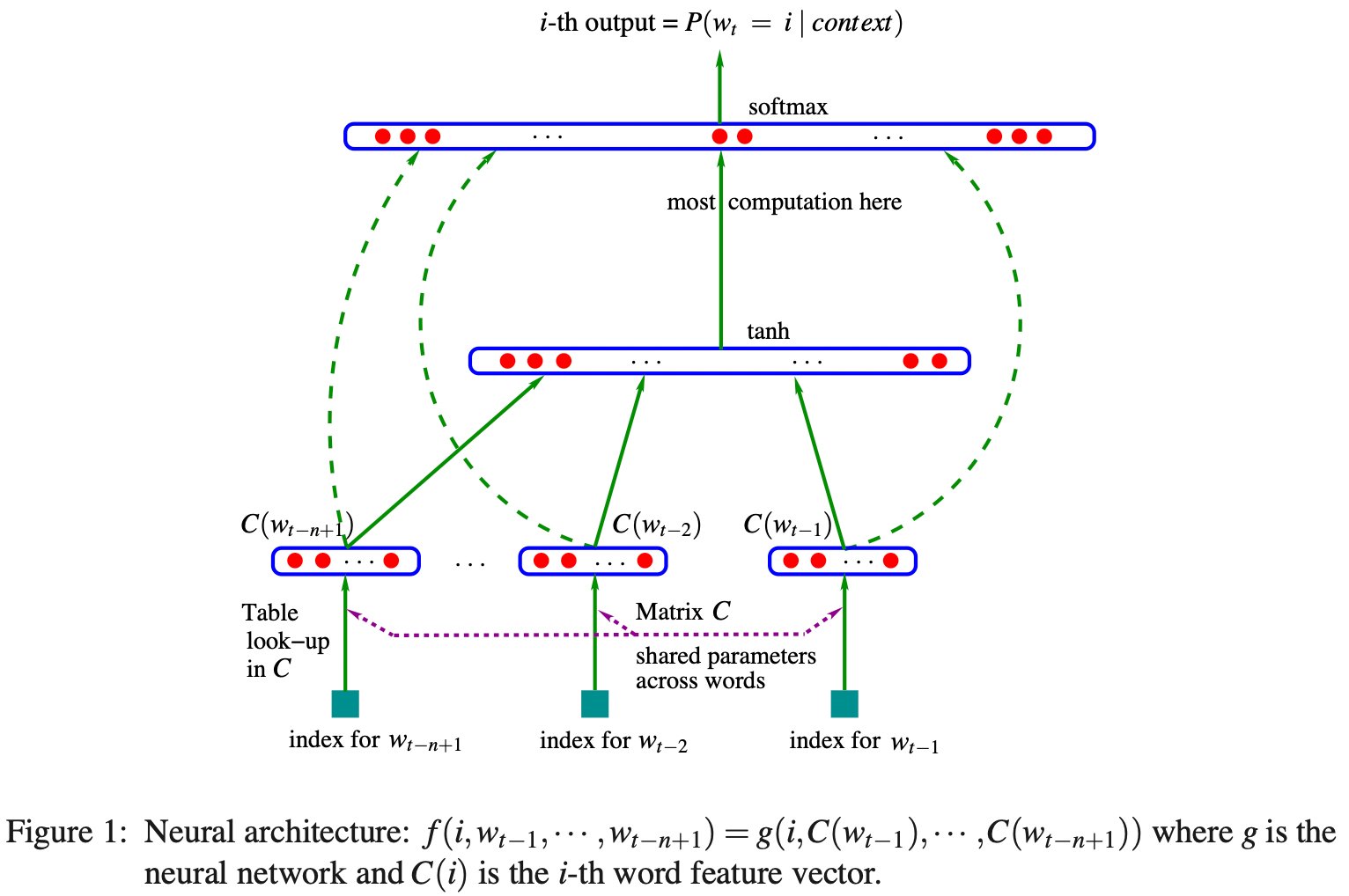
E.g. ~20 years ago Bengio et al 2003 (pdf: https://jmlr.org/papers/volume3/bengio03a/bengio03a.pdf…) trained a neural language model. The state of the art GPT+friends of today are the exact same (autoregressive) model, except the neural net architecture is upgraded from an MLP to a Transformer.
Andrej Karpathy @karpathy 2022-11-18
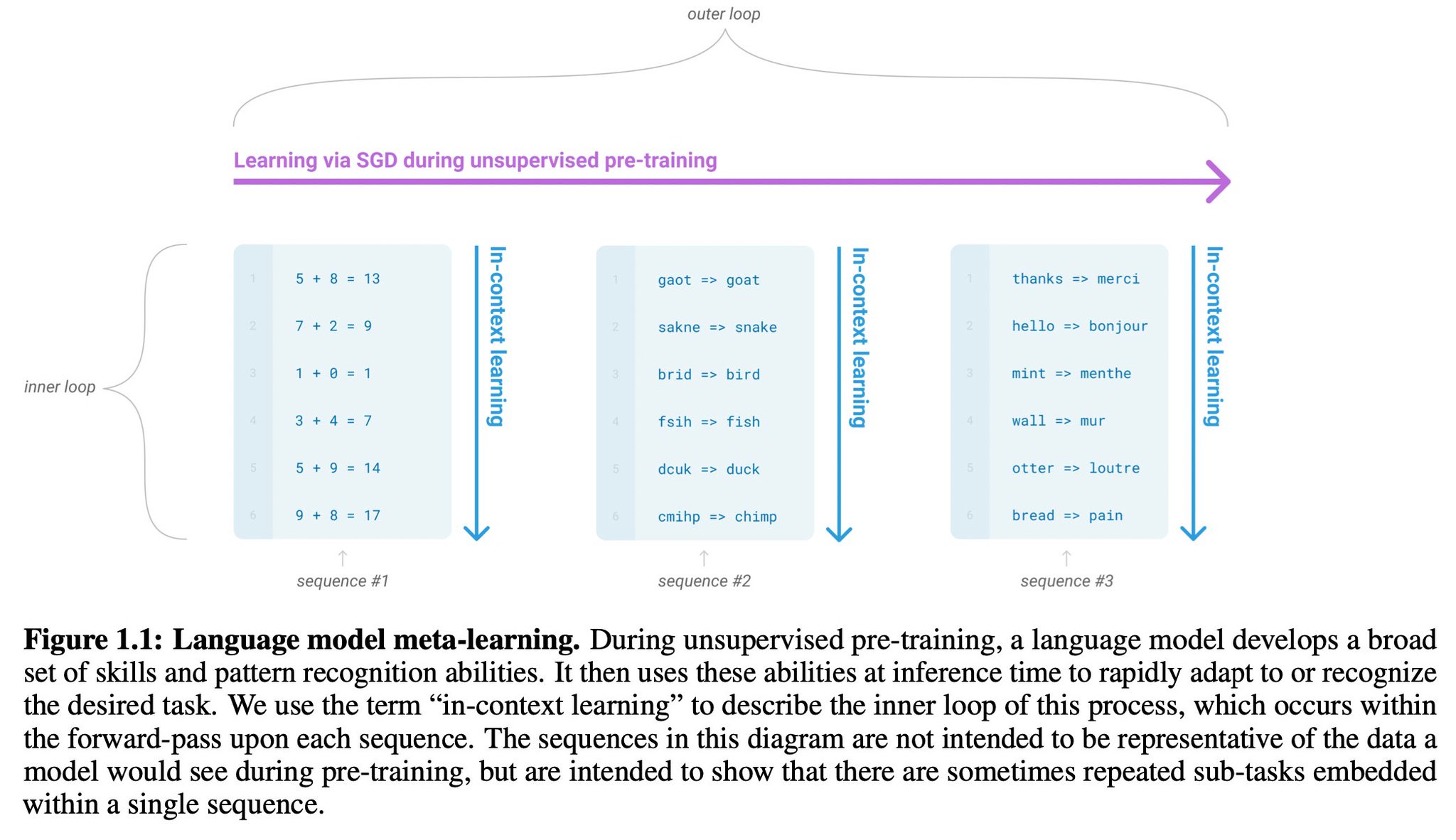
The non-obvious crux of the shift is an empirical finding, emergent only at scale, and well-articulated in the GPT-3 paper (https://arxiv.org/abs/2005.14165). Basically, Transformers demonstrate the ability of “in-context” learning. At run-time, in the activations. No weight updates.
Andrej Karpathy @karpathy 2022-11-18
If previous neural nets are special-purpose computers designed for a specific task, GPT is a general-purpose computer, reconfigurable at run-time to run natural language programs. Programs are given in prompts (a kind of inception). GPT runs the program by completing the document
Andrej Karpathy @karpathy 2022-11-18
So the first critical “unlock technology” is the Transformer, a neural net architecture powerful enough to become a general-purpose computer. I’ve written more about this here: 1) https://x.com/karpathy/status/1582807367988654081… and 2)
2021-12-08
The ongoing consolidation in AI is incredible. Thread: ➡️ When I started ~decade ago vision, speech, natural language, reinforcement learning, etc. were completely separate; You couldn’t read papers across areas - the approaches were completely different, often not even ML based.
Andrej Karpathy @karpathy 2022-11-18
The second critical ingredient is that while a Transformer seems ~able to act as a general-purpose computer in principle, the training objective has to be hard enough to actually force the optimization to discover and converge onto it in the “weights space” of the network.
Andrej Karpathy @karpathy 2022-11-18
Turns out language modeling (i.e. ~next word prediction; equivalent to compression) of internet text is this excellent objective - v simple to define and collect data for at scale. It forces the neural net to learn a lot about the world, “multi-tasking” across many domains.
Andrej Karpathy @karpathy 2022-11-18
TLDR: LMs have been around forever. Not obvious finding: turns out that if you scale up the training set and use a powerful enough neural net (Transformer), the network becomes a kind of general-purpose computer over text.
Andrej Karpathy @karpathy 2022-11-18
I wrote this thread because I spent the last ~decade, obsessing over directions that would make fastest progress in AI, and was very interested in language models (e.g. my semi-famous 2015 post “The Unreasonable Effectiveness of Recurrent Neural Networks” https://karpathy.github.io/2015/05/21/rnn-effectiveness/…)
Andrej Karpathy @karpathy 2022-11-18
But I still mispredicted in how much fertile ground there was in scaling up the paradigm. Like many others in AI I got distracted by Reinforcement Learning too soon, a kind of putting the cart before the horse, …
Andrej Karpathy @karpathy 2022-11-18
when the core unlock was achieving a kind of general-purpose computer neural net via simple scalable objectives that have strong training signal (many bits of contraints per training example). Like language modeling, and not like reinforcement learning.
So that was interesting :D
Shen Yang @shenyang 2023-04-14
@threadreaderapp unroll
Thread Reader App @threadreaderapp 2023-04-14
@shenyang Hola, here is your unroll: https://threadreaderapp.com/thread/1593417974433517569.html… See you soon. 🤖
Philippe Tremblay @philtrem22 2022-11-18
Reading this made me wonder: are there any effort to use AI models to go from code to machine code. I.e. Where the model acts as a compiler.