Anyone who has been part of the software development industry knows that resolving merge conflicts is just part of the game, and if you’re starting out, you’ll soon realize it as well!
But what is a merge conflict? And why do conflicts occur? Can they be avoided?
In this post, I’ll answer the above questions so you can learn how to avoid conflicts in the first place and effectively resolve them when you have to.
The merge dilemma
Whenever two or more developers make changes to the same file respectively and later try to fuse the versions, merge conflicts will likely occur. Heck, you can even produce a conflict with yourself if you’re touching the same file in two different branches and later joining them together.
If we forget any version control system for a while and consider this concrete case, where two developers, Ada and Bob, have both made changes to the same pre-existing index.html file, ultimately producing one new revision each. How can these two revisions later be merged without losing any of the respective changes?
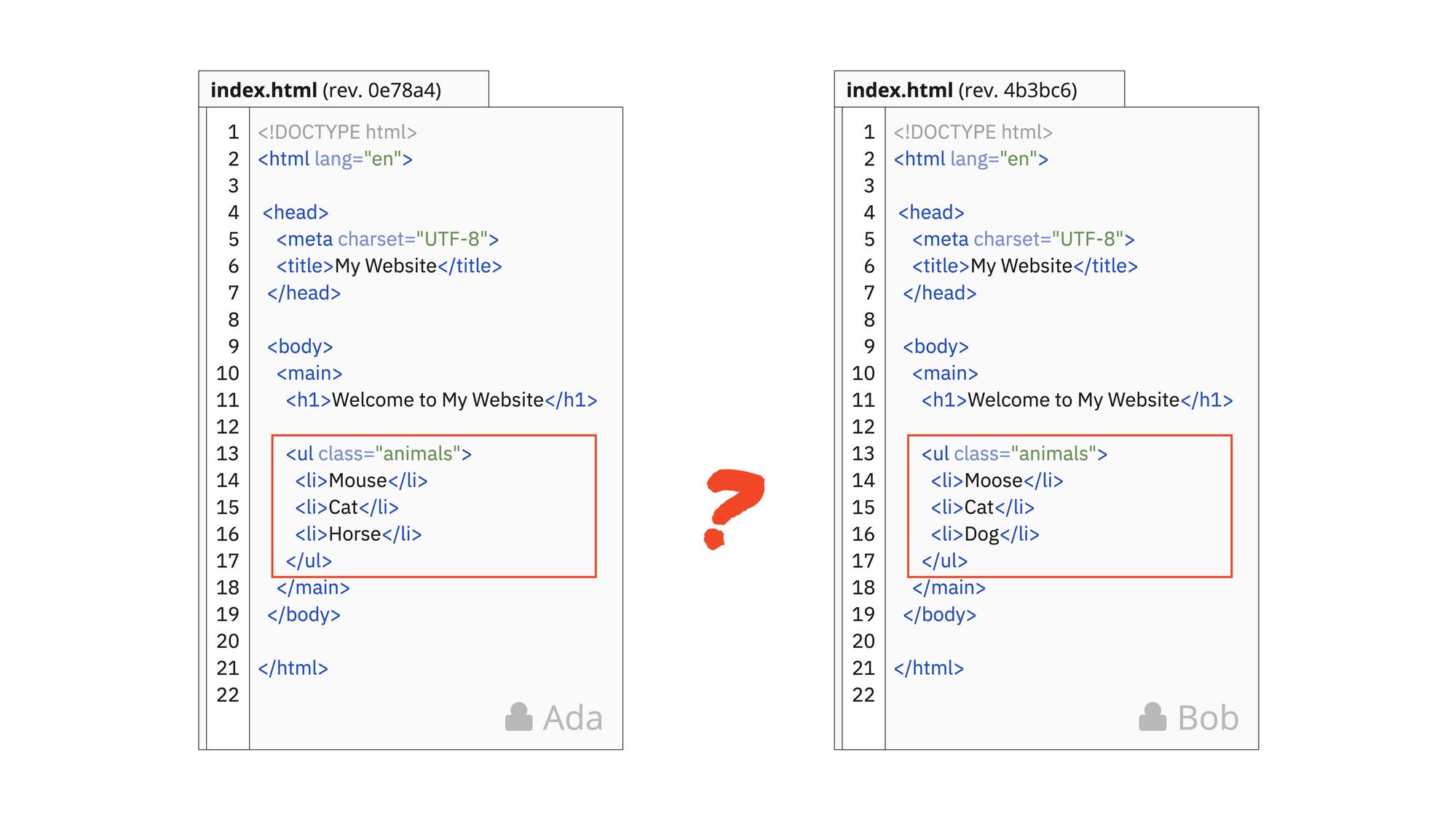
A simple two-way comparison of an index.html file that’s been changed by the developers Ada and Bob, respectively.
First, we need to figure out how the files differ. Notice how they’ve both changed the <ul> block, tinkering with the unordered list of animals. How would you do it if you were tasked to produce a final merged version from the two revisions?
The merge dilemma is this:
- Did Ada change
MoosetoMouseor did Bob changeMousetoMoose? - Were
HorseandDogadded to the list by each developer, respectively? - Or did any or both of the two developers update the final item in the list from a previous entry?
Given the information you have, it’s impossible to know! This scenario is what’s known as a two-way (2-way) merge, where two revisions are statically compared and manually fused.
But how can the merge be completed, given the dilemma? The only way is to talk to each developer to figure out what they changed respectively and then produce a final version accordingly — a tedious and time-consuming matter!
Thankfully there’s a clever solution known as a three-way (3-way) merge!
3-way merge to the rescue!
Instead of manually backtracking what changes each developer made, three-way merge does just that for us! This is because modern version control systems, such as Git, can automatically find what’s known as the “nearest common ancestor”, aka base revision (or merge-base). It is called “3-way” since it uses three revisions to produce a final merged version.
With a base revision identified, figuring out what changed to produce a desired final version is a piece of cake. Consider the case below again, but introduce the base revision that Ada and Bob based their changes on initially.
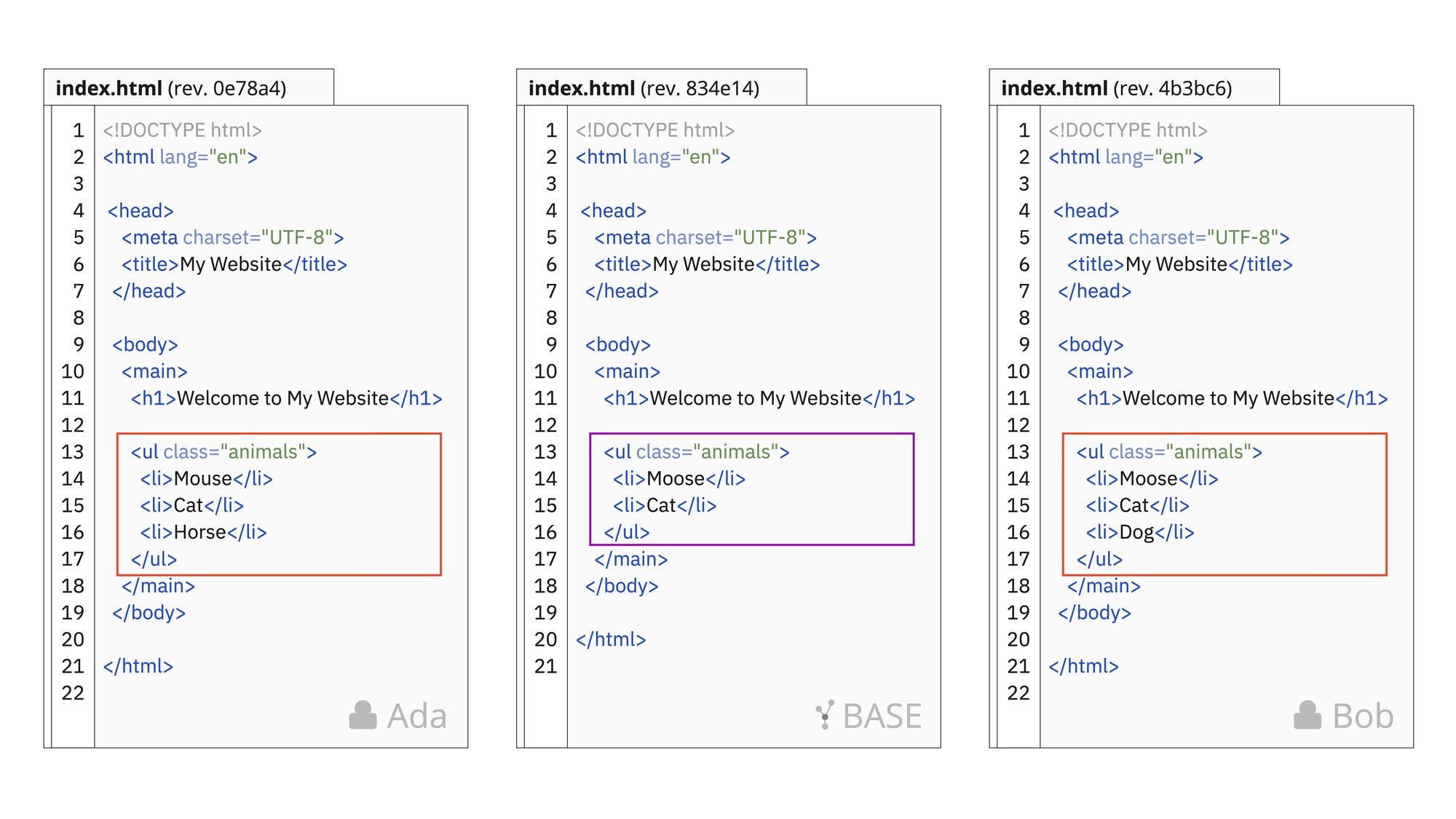
Comparison of two revisions made by Ada and Bob, respectively, with their nearest common ancestor in the middle.
Looking at the above comparison of the three revisions, it’s now much easier to figure out what the final version should look like. Starting with Moose or Mouse it’s clear that Bob didn’t change this line, but Ada did! Regarding the last item, both of the two added a new animal to the list, Horse and Dog respectively.
Using the three-way merge strategy, we can use this newly gained information to produce a resulting version! And, it turns out — as we’ll see — not all of these conflicts have to be manually resolved.
The resulting merge
With Git or any other version control system capable of producing a three-way merge, conflict resolution is bliss! So, again, let’s look at our example from earlier, but this time only focus on the part of the file that changed between Ada’s and Bob’s revisions.
Below, in the upper row, we have the revisions from Ada and Bob on each side and the base revision in the middle. Finally, the revision illustrating the resulting merge is shown on the bottom row.
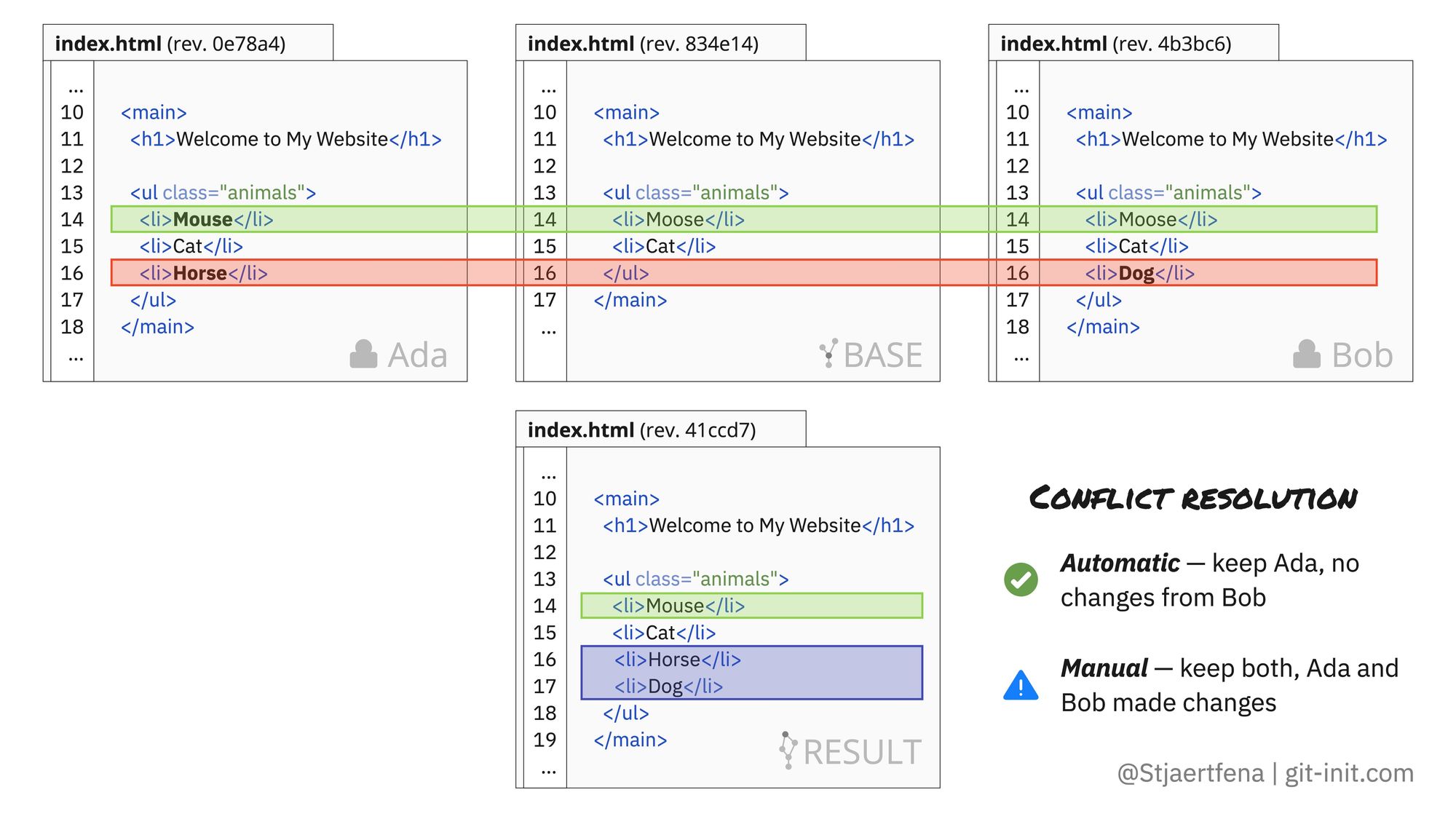
Post-merge revision of index.html with all conflicts resolved.
As it turns out, the initial “conflict” was no conflict at all, as Ada was the only one who made changes to the first item in the <ul>, and hence, Git “resolved” this automatically for us. But, the change to the final item requires manual intervention as Git cannot figure out what the result should look like. However, it is clear that both Ada and Bob added a new animal to the list, so we can manually resolve this by keeping both changes!
Want to see how manual conflict resolution works in practice? Check out this post!
Unstructured vs. structured merge
Speaking of merges, it’s worth mentioning that there are two types of algorithms out there, structured and unstructured.
- Unstructured merge operates on raw text, typically using lines of text as atomic units. For example, Unix tools (diff/patch) and CVS tools (SVN, Git) use this. However, this worldview is limited, as a line of text does not represent the structure of source code.
- Structured merge or AST (Abstract Syntax Tree) merge turns the source code into a fully resolved AST. This allows for a fine-grained merge that avoids spurious conflicts. In other words, AST merge is aware of what content it is trying to merge, such as a Java program.
Why conflicts occur
Hopefully, it should now be clear why conflicts occur and what can be done to avoid them. In short, with Git, merge conflicts only occur when two revisions of the same file are fused, if and only if changes have been made to the same section. Typically this happens when two or more developers work on different branches but make changes to the same file and section.
As long as changes are made in different parts of a file, Git uses a three-way merge strategy to figure out what to keep and merges automatically. To avoid nasty conflicts requiring manual interventions, don’t make concurrent changes to the same portion of a file whenever possible!
And finally, don’t be fooled when someone says, “Git is very good at merging”. They mean that “Git is very good at tracking the history. Hence, calculating the common ancestor for each file is quick and easy, and therefore resolving simple conflicts is automatic”.
Key takeaways
- Git is no antidote to merge conflicts, but it’s incredibly clever at merging file histories as long as changes aren’t made to the same lines.
- Git is unaware of what “software” you are merging. Instead, it operates on raw text.
- Three-way merge is by far the better option than two-way merge, and it’s the strategy used by Git. It is called “3-way” since it uses three revisions to produce a final merged version.
- When merging branches, as long as changes are made to different files or sections of the same file, Git will merge everything automatically.
- The only way to avoid potential merge conflicts is by having good communication within the team, and not touching the same file section.
😎 Thanks for reading, and good luck improving your source code management skills!
If you’d like more pieces like this, subscribe to the news feed; to avoid missing anything! By subscribing, you’ll also get access to members-only content!
If you have any questions or suggestions, try reaching me on Twitter – @Stjaertfena